23
Feb
What is the best compute architecture for vRAN/open RAN?

When the telecom industry is busy with Mobile World Congress preparations, taking stock of the vRAN/open RAN market and the key emerging trends, especially the compute architecture, is worthwhile.
It is becoming clear that companies that provide advanced technologies, feature parity (or superiority) with legacy RAN, and the most power- and cost-efficient solutions will win the race.
vRAN/open RAN – operators’ primary considerations
As operators embark on their journey, it is getting clear that it will be a two-step process. First, a single vendor vRAN with open interfaces. Second, multi-vendor open RAN. This approach minimizes the system integration burden and enables smooth migration. They are also realizing that outlandish cost-saving claims of open RAN are not true. If at all, the initial deployments will be more expensive. But, the hope is that without vendor lock-in, the second step might bring cost savings.
Feature parity with established 5G networks is becoming another critical consideration. While initial vRAN/open RAN deployments only had simpler 4T4R and 8T8R MIMO configurations, the more advanced 32T32R and 64T64R are beginning to happen. 5G itself and many such features were delayed in vRAN/open RAN. Parity becomes even more important when commercializing Rel. 17 and Rel. 18. features. These bring additional processing complexity, creating another major challenge — power efficiency.
In a recent survey conducted by GSMA Intelligence, energy efficiency came as the top consideration for operators, even higher than security.
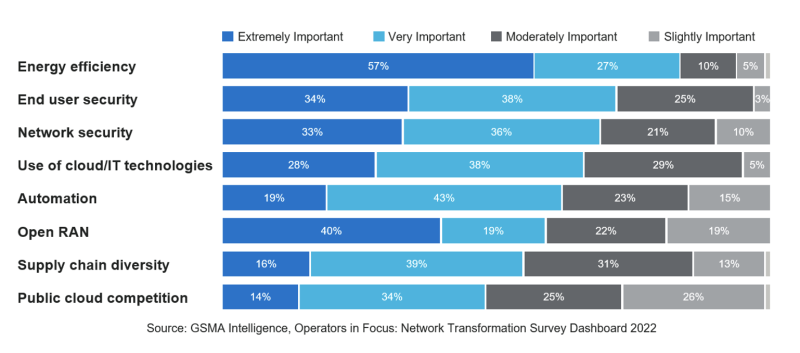
The reason energy efficiency is this high is twofold. First, fundamental operational and financial needs, and second, climate change compulsions. Reducing carbon footprint and becoming carbon neutral is in almost every operator’s corporate charter.
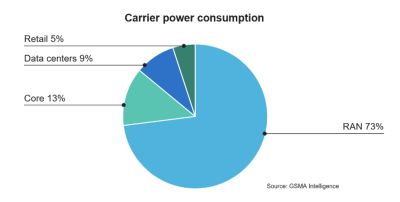
The most effective option for operators to save energy is in RAN. GSMA Intelligence estimates that RAN accounts for a whopping 73% of operators’ total power consumption. That is apparent, as each operator has hundreds of thousands of base stations. Even a slight improvement in energy efficiency in base station components can have a significant impact. So, suffice to say, power consumption is one of the most, if not the most, important considerations when operators evaluate vRAN/open RAN solutions.
The best compute architecture
One of the key things holding off vRAN and open RAN for this long, while the core network has been virtualized for a long time, is the critical and demanding nature of RAN workloads. The complexity lies in Layer-1 (aka physical layer or PHY) processing.
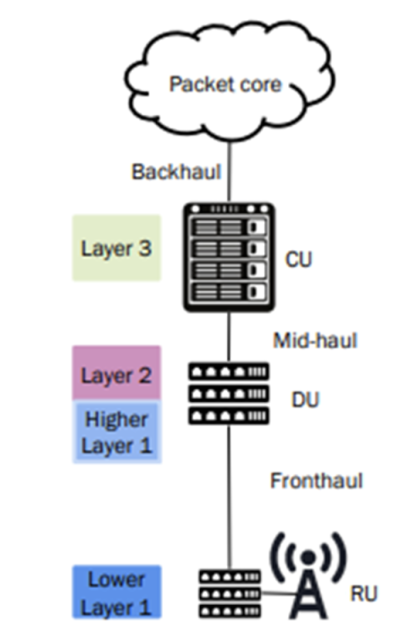
vRAN/open RAN comprises of three parts. First is the Central Unit (CU), which manages Radio Resource Control and Packet Data Convergence Protocol functions. The Second is the Distributed Unit (DU), which manages Radio Link Control, Medium Access Control, and PHY. And third is the Radio Unit (RU), which manages digital-to-analog conversion, MIMO antenna management, and others.
From a protocol perspective, CU manages Layer-3 and part of Layer-2. DU manages part of Layer-2 and part of Layer-1. RU manages the remaining portion of Layer-1. The complexity, latency constraints, and processing needs drastically increase as you move down from Layer-3 to Layer-1. In fact, Layer-2 and 1 together consume almost 90% of the processing power of RAN.
0 comments